
Where engineering leaders get their systems wrong
I’ve spent a fair amount of time over the past year looking at how teams are actually building with AI.
Not demos. Not prototypes. Real systems people are expected to rely on.
A pattern shows up pretty quickly.
These systems don’t break immediately. They break over time. They give just enough correct answers to feel useful, and just enough wrong ones to make people hesitate. You can watch the shift. At first people trust it. Then they double check. Eventually they work around it.
When that happens, the model gets blamed.
In most of the cases I’ve seen, it wasn’t the model. It was the design.
A few architectural patterns show up over and over. None of them are wrong. The problem is how they’re applied.
Part of why this keeps happening is subtle. These decisions don’t come from carelessness, but momentum. Teams reach for the pattern they saw most recently. The one that they read about or saw in a YouTube video. I’ve seen “enterprise-grade” systems assembled from ideas someone picked up in a video a few weeks ago. The system gets built before the problem is shaped.
Retrieval-augmented systems
This is where most teams start.
Take a set of documents, chunk them, embed them, retrieve the most relevant pieces at query time, and pass that into the model.
On paper, it makes sense. The model stays grounded. No retraining. It works for simple questions.
The boundary shows up when the questions stop being simple.
If a question can be answered by a single paragraph in your data, basic retrieval will work. If it requires combining sources, comparing versions, or applying context over time, it won’t.
Most retrieval systems aren’t built for that. They’re built for similarity.
So you get a familiar pattern:
- a few chunks come back that look relevant
- the model assembles something coherent
- the answer sounds reasonable
- but it’s incomplete, or slightly wrong
I’ve seen teams respond to this by pulling in more context. It feels like progress. It usually makes things worse.
At some point the model isn’t reasoning over context. It’s just summarizing noise.
The issue isn’t retrieval itself, but treating retrieval as if it solves reasoning.
If the problem requires multi-step understanding, the system has to reflect that.
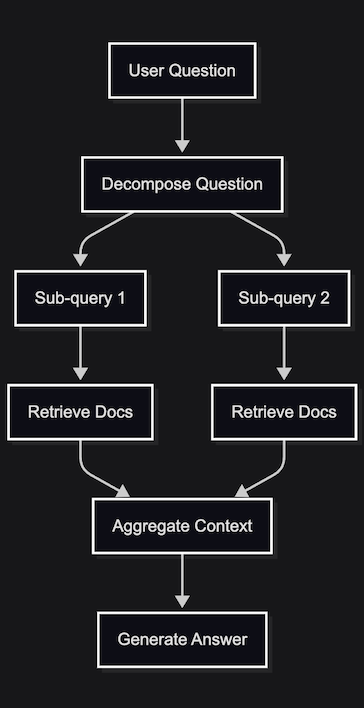
Most teams skip the decomposition step.
What they have isn’t a knowledge system. It’s a retrieval shortcut.
Data-fed systems without a data model
This one looks fine early on.
Documents get ingested. Embeddings get created. The pipeline runs. You can query it.
Underneath, the data is a mess.
The same concept exists in multiple places. Some versions are outdated. Some contradict each other. There’s no clear sense of which source is authoritative.
The model doesn’t know that.
It sees all of it and tries to produce a consistent answer.
That’s when you get responses that read well but don’t hold up. The language is clean. The reasoning is plausible. The facts don’t quite line up.
People call this hallucination. In most of the systems I’ve heard of, it wasn’t. It was inconsistent input.
A good data model does something simple but critical. It tells the system which version of a fact wins. It encodes authority, freshness, and ownership so retrieval returns a coherent view instead of a blend.
In practice, that usually means:
- attaching metadata to every source (timestamp, owner, audience)
- defining a precedence rule (which source wins when they conflict)
- filtering retrieval based on permissions and context
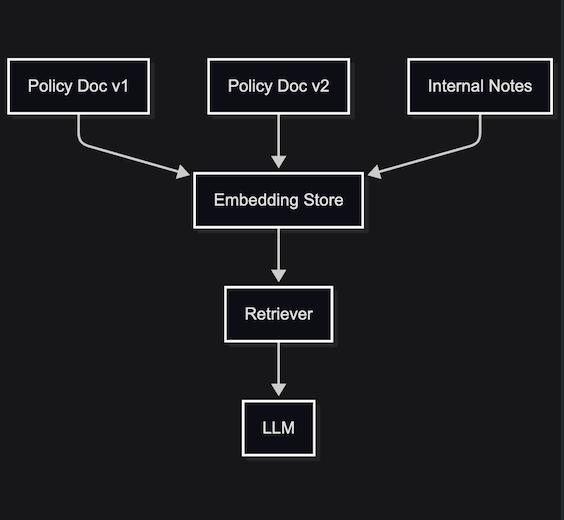
There’s no notion of source of truth, freshness, ownership, or permissions.
The model doesn’t resolve that. It smooths it over.
Teams treat this as a pipeline problem. In practice, it’s a modeling problem.
Until the system knows what is true, it will keep producing answers that are merely consistent.
Agent-based systems for structured problems
At some point, teams decide to make it an agent.
The appeal is obvious. Instead of a fixed flow, the system can decide what to do. It can call tools, plan steps, and adapt.
Useful in the right context, but overused in most of them.
I was looking at a system not long ago where an agent had been added on top of a retrieval layer that wasn’t returning the right information. The agent would retry queries, call different tools, and eventually land on something usable. It looked intelligent. What it was actually doing was compensating for a broken retrieval step.
You end up with a loop that hides problems instead of surfacing them.
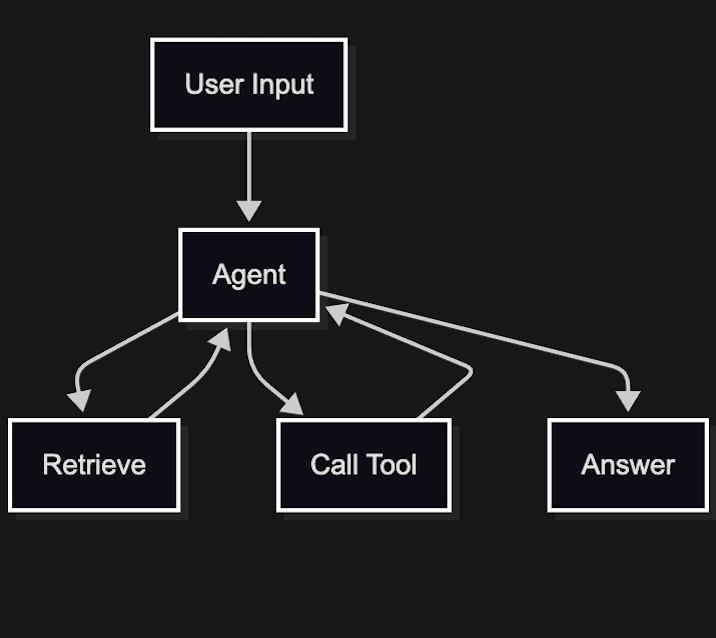
When it works, it looks impressive. When it fails, it’s hard to diagnose. The same input can take a different path each time, and the reasoning is buried in intermediate steps.
For structured problems, the failure is predictable. You’ve replaced explicit decisions with implicit ones.

This isn’t flexibility versus rigidity, but visibility. In a workflow you can see where decisions are made and change them. In an agent loop you infer it after the fact.
Agents make sense when the path is unknown and the system needs to explore. They’re a poor fit when the path is known but hasn’t been made explicit.
If an agent is consistently “recovering” from earlier steps, that’s usually a sign those steps need to be fixed, not wrapped.
Fine-tuned systems solving the wrong problem
This shows up later, once everything else is in place.
The system is close. Outputs are decent, but inconsistent. The format drifts. The tone isn’t quite right.
So the next step is to fine-tune.
That works when the problem is behavior, but not when the problem is structure.
If your system retrieves the wrong data, combines conflicting sources, or executes the wrong flow, training the model harder won’t fix it.
What it does instead is make the system more rigid.
Now you’ve encoded assumptions into the model. Updating behavior requires retraining. Debugging gets harder because the logic isn’t entirely in the system anymore.
You end up with something that looks more polished but is still wrong in the same places.
Fine-tuning is good at shaping how the model responds, but it doesn’t change what the system feeds into it.
A quick way to spot the mismatch
| If your problem is… | Don’t reach for… | Instead, try… |
|---|---|---|
| Multi-step logic | More context/chunks | Query decomposition / chains |
| Conflicting data | A smarter model | A semantic data model / authority rules |
| Unreliable flows | An autonomous agent | A deterministic workflow |
| Bad formatting | RAG / prompting | Fine-tuning |
The question that gets skipped
Before choosing a model, a tool, or a pattern, there’s a simpler question that rarely gets asked.
What kind of system is this?
That question isn’t about labels. It determines how the system behaves under pressure.
If it’s a lookup system, completeness matters less than precision. If it’s a reasoning system, retrieval has to be structured, not just relevant. If it’s a workflow, control and observability matter more than flexibility. If it’s exploratory, you accept variability and design around it.
Most of the failures above come from crossing those boundaries without noticing.
A lookup system asked to reason. A reasoning system built on inconsistent data. A workflow hidden inside an agent loop. A structural problem pushed into fine-tuning.
These aren’t dramatic mistakes. They’re small mismatches that compound as the system grows.
The model gets blamed because it’s the most visible part. The design set the constraints.
By the time you notice it, the system already has shape. And now you’re not fixing a model.
You’re unwinding a set of decisions you made before you understood the problem.
Related reading
If you want to go deeper on the specific failure modes behind this argument:
- Where AI Systems Drift for a layer-by-layer breakdown of where controls belong
- The RAG Atlas - A Visual Guide to Retrieval Patterns for retrieval design tradeoffs and pattern selection
- Prompt Debt - The Silent Failure Mode Inside Modern AI Systems for how context and instruction layers quietly become architecture